

Dans la première partie que vous retrouverez ici, nous abordions les premiers types de bases de données (BD) à voir le jour. Dans ce second et dernier volet, nous verrons de nouveaux paradigmes de BD nés des besoins créés par l’Internet, les réseaux sociaux ainsi que la nécessité de gérer une quantité phénoménale de données collectées par ses entreprises et que nous nommons mégadonnées (Big Data).
Dans cette suite, je vous donne ici les principaux paradigmes de BD, leurs applications et des exemples d’entreprises qui les utilisent.
Avant d’aller plus loin, il est important de noter qu’à l’ère des données massives et de la pluralité des services disponibles, il est fréquent de voir des entreprises utiliser plus d’un paradigme pour mener à bien leurs opérations. Ceci explique les noms d’entreprises que vous pourriez voir apparaître plus d’une fois.
Parfois, il peut sembler que la ligne soit floue entre certains produits, les entreprises amalgamant deux, voire plusieurs paradigmes dans leur gestion des données pour répondre à l’ensemble de leurs besoins. Sachez que, malgré les apparences, chacun a son utilité. Par ailleurs, la plupart de ses paradigmes sont utilisés en complémentarité l’un avec l’autre afin de tirer avantage de chacun.
De nouveaux paradigmes de bases de données dits NoSQL
Comme mentionné ci-haut, de nouvelles façons de gérer les données sont nées de besoins créés par les nouvelles technologies, mais aussi par l’accumulation massive de données de toutes sortes.
Petit rappel, à la fin de la première partie, j’avais mentionné que ses nouveaux paradigmes se classent dans une famille de BD nommée NoSQL, c’est-à-dire qu’elle s’écarte du paradigme classique des BD relationnelles. La plupart de ces nouveaux paradigmes ont été élaborés pour répondre à des besoins de données non structurées, contrairement aux paradigmes que nous avons vus jusqu’à maintenant.
Base de données à clé-valeur
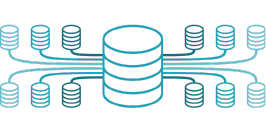
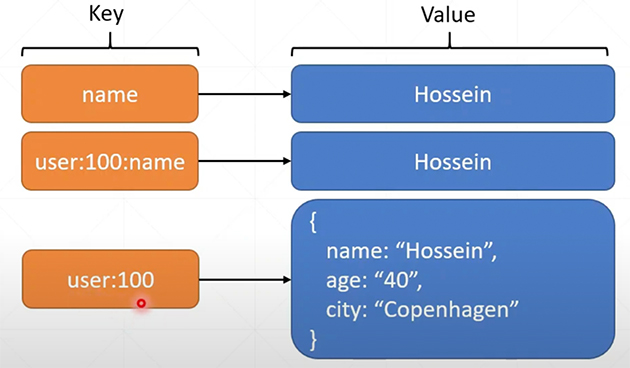
Les bases de données à clé-valeur (key-value database) utilisent une clé pour identifier une information, un groupement d’informations, un tableau associatif ou un objet complexe. Ce type de BD fonctionne entièrement en mémoire, limitant ainsi les accès au disque. Ceci offre une performance inégalée, mais limite la taille en fonction de la capacité mémoire de l’ordinateur.
Finalement, elles permettent une recherche rapide d’informations dans une mer de données et se prêtent bien à la programmation orientée objet. Fait à noter, ce type de BD est souvent utilisé pour sa performance et en collaboration avec d’autres paradigmes qui peuvent contenir davantage de données.
Des exemples de logiciel
Des exemples d’utilisation
Base de données à larges colonnes
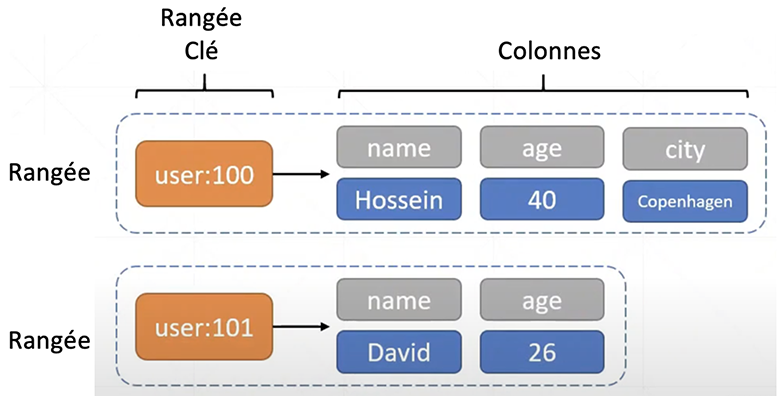
La BD à larges colonnes est un paradigme de données qui utilise des tables en lignes et colonnes. Ce type de base de données a été pensé afin de gérer de grandes charges de travail analytiques et opérationnelles. L’interrogation de cette BD s’effectue via le langage CQL (Contextual Query Language)
Encore une fois, cette BD ne sera pas primaire, mais complémentaire à un autre paradigme. Le but est simplement d’augmenter les performances.
Des exemples de logiciels
Des exemples d’utilisation
Base de données orientée documents
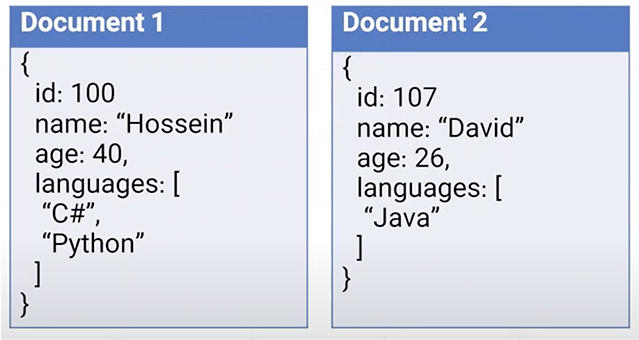
La BD orientée documents permet de gérer les informations sous forme de documents regroupés dans des « magasins de documents » ou collections. Les principaux avantages sont une plus grande souplesse pour les développeurs et une flexibilité du schéma qui permet à la BD d’évoluer avec les besoins de l’entreprise. Entre autres, chaque document n’a pas l’obligation d’avoir les mêmes champs, contrairement aux BD traditionnelles.
Des exemples de logiciels
Des exemples d’utilisation
- Equifax
- WalmartLabs OneOps (division infonuagique de Walmart).
Base de données en texte intégral
Les BD en texte intégral ou BD plein texte contiennent le texte complet de livres, revues, journaux ou autres types de documents et sites Internet. Elles partagent des similarités avec les BD orientées documents à la différence que chaque terme est indexé afin de créer un index de termes, un peu comme on retrouve dans un livre, avec références aux documents ou sites concernés.
Il n’y a pas de limite à la longueur de champ, contrairement à la plupart des autres types de BD. Les BD plein texte permettent de répondre à toute recherche de l’utilisateur sur leur contenu.
Ce type de BD est primé auprès des moteurs de recherche.
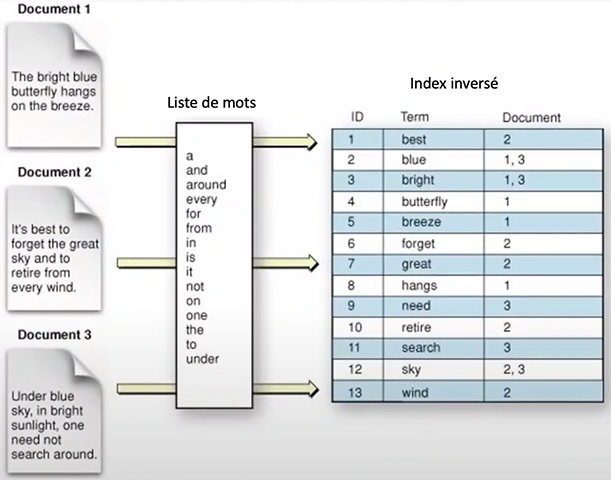
Exemples de logiciels
Exemples d’utilisation
Base de données orientée graphe
La BD orientée graphe est orientée objet, c’est-à-dire qu’elle groupe l’information sous forme de collections d’objets persistants. Elle utilise la théorie des graphes connue en mathématique. Ce modèle abstrait encapsule les données, que nous nommons nœuds, puis les relations entre ses nœuds sont nommées des « edges », créant ainsi des réseaux d’informations. Vous le devinerez, ce type de BD est primé par les réseaux sociaux.
L’interrogation de ce type de BD s’effectue à l’aide du langage Cypher.
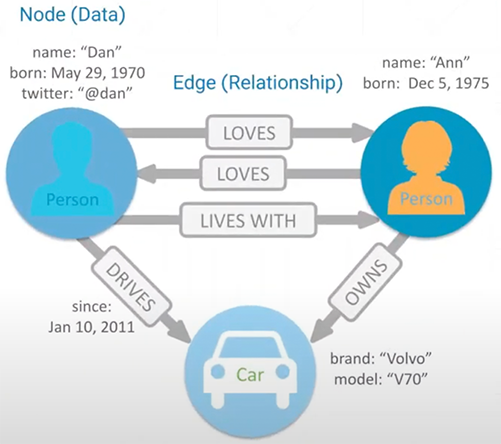
Exemples de logiciels
Exemples d’utilisation
Base de données de séries chronologiques
Les BD de séries chronologiques, de l’anglais Time series database ou TSDB, sont spécialisés pour organiser les informations mesurées dans le temps. Celles-ci sont primées dans le monde de la finance et l’Internet des objets (Internet of things ou IoT) où une quantité importante de données est acheminée et doit être traitée rapidement. L’avantage est la constance des performances dans le temps au fur et à mesure de l’augmentation de la quantité de données ingérées. Le graphique suivant en donne une idée.
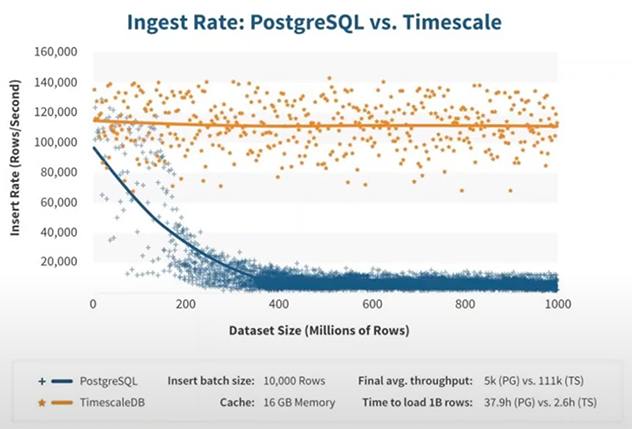
Exemples de logiciels
Exemples d’utilisation
- New York Stock Exchange (NYSE)
- Agence spatiale européenne (esa)
Base de données multimodèle
La BD multimodèle est, je crois, l’une des plus intéressantes de tout ce que nous avons vu jusqu’à maintenant. Elle utilise les paradigmes que nous avons vus précédemment, le tout en un seul produit. Ce type de SGBD (système de gestion de bases de données) est plutôt rare, mais très versatile. L’un des avantages mis de l’avant est que vous n’avez qu’à fournir les données et schémas de données, comment vous voulez y accéder et ce que vous voulez en faire. Le logiciel s’occupera de déterminer le ou les meilleurs paradigmes pour répondre à vos besoins.
Cette structuration et l’interrogation des données s’effectuent à l’aide d’un langage de requête nommé GraphQL.
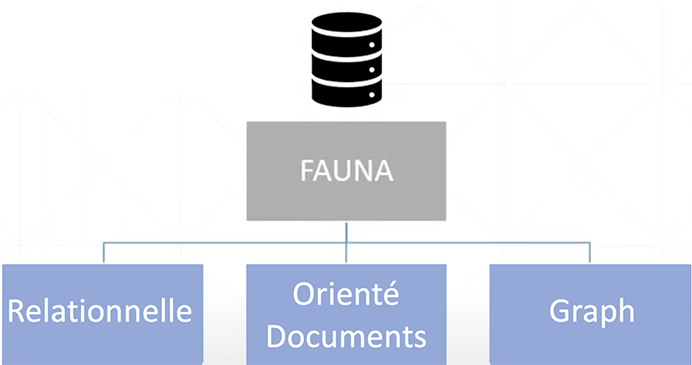
Exemple de logiciel
Exemples d’utilisation
Bases de données distribuées
Ici, il ne s’agit pas d’un paradigme, mais d’un mode de fonctionnement. J’avais envie de terminer sur une note plus légère. Si vous vous demandez comment sont gérés les millions de données recueillis par les centaines de capteurs que contient une voiture de Formule 1 (F1) lorsqu’elle est en piste, tel que j’en faisais mention dans cet autre article sur la technologie en F1, la BDD (base de données distribuées) est utilisée.
Bien que le paradigme utilisé soit essentiellement une base de données relationnelle, comme nous avons vu dans le premier article, celle-ci est distribuée sur un réseau d’ordinateurs interconnectés afin d’offrir la performance requise à la quantité de données à traiter en temps réel.
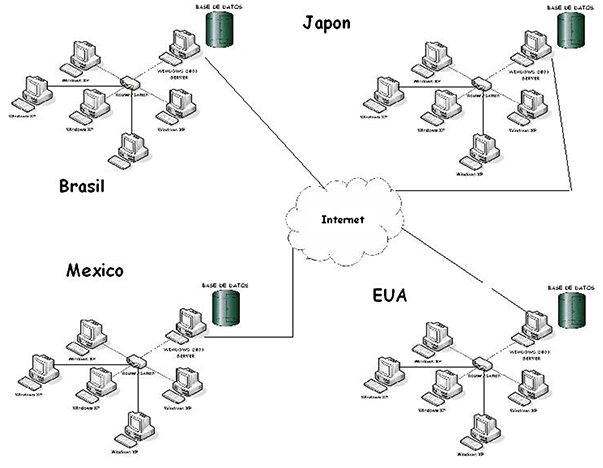
Exemple de logiciel
Exemple d’utilisation
Voilà qui fait un tour non exhaustif de différents paradigmes de bases de données utilisés de nos jours. Bien entendu, la recherche ne cesse de progresser en technologie. Qui sait ce qui se développe actuellement dans ce domaine pour répondre aux besoins de demain avec la montée de l’intelligence artificielle qui utilise déjà certains de ces paradigmes, mais aussi avec la montée de l’informatique quantique.
Informatiquement vôtre,
Daniel Vinet
Voici une base de données de bases de données! -> https://dbdb.io/
Voici un projet éducatif visant à décortiquer le fonctionnement des bases de données distribuées -> https://github.com/erikgrinaker/toydb
Il y a de quoi s’amuser longtemps! Redis est disponible en version libre depuis le 1er mai -> https://redis.io/open-source/
Il y a beaucoup de bases de données en version libre pour séries chronologiques ->
https://medevel.com/time-series-database-1764/
https://sourceforge.net/software/time-series-databases/free-version/
Pour les bases de données de graphes, il y a -> https://opencypher.org/
Bonjour M. Côté. Merci de ses ajouts.
Bravo, Daniel, beau travail bien expliqué et simplifié avec de bons exemples en plus!
Bonjour Marius et merci de ton commentaire, j’apprécie beaucoup.